### What happened + What you expected to happen
When logging custom metrics to …wandb via `WandbLoggerCallback` the metrics are duplicated and visible as:
- `custom_metrics/*'
- `sampler_resutls/custom_metrics/*`
I would expect to see just `custom_metrics/*` I have implemented.
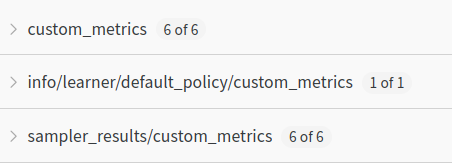
After some drilling I found most probably responsible line https://github.com/ray-project/ray/blob/master/rllib/algorithms/algorithm.py#L2541
with potentialy related `# TODO: Don't dump sampler results into top-level.`
### Versions / Dependencies
1.13.0
### Reproduction script
Modified example from https://github.com/ray-project/ray/blob/master/rllib/examples/custom_metrics_and_callbacks.py enriched with WandbLoggerCallback
```
"""Example of using RLlib's debug callbacks.
Here we use callbacks to track the average CartPole pole angle magnitude as a
custom metric.
"""
from typing import Dict, Tuple
import argparse
import numpy as np
import os
import ray
from ray import tune
from ray.rllib.agents.callbacks import DefaultCallbacks
from ray.rllib.env import BaseEnv
from ray.rllib.evaluation import Episode, RolloutWorker
from ray.rllib.policy import Policy
from ray.rllib.policy.sample_batch import SampleBatch
from ray.tune.integration.wandb import WandbLoggerCallback
parser = argparse.ArgumentParser()
parser.add_argument(
"--framework",
choices=["tf", "tf2", "tfe", "torch"],
default="tf",
help="The DL framework specifier.",
)
parser.add_argument("--stop-iters", type=int, default=2000)
class MyCallbacks(DefaultCallbacks):
def on_episode_start(
self,
*,
worker: RolloutWorker,
base_env: BaseEnv,
policies: Dict[str, Policy],
episode: Episode,
env_index: int,
**kwargs
):
# Make sure this episode has just been started (only initial obs
# logged so far).
assert episode.length == 0, (
"ERROR: `on_episode_start()` callback should be called right "
"after env reset!"
)
print("episode {} (env-idx={}) started.".format(episode.episode_id, env_index))
episode.user_data["pole_angles"] = []
episode.hist_data["pole_angles"] = []
def on_episode_step(
self,
*,
worker: RolloutWorker,
base_env: BaseEnv,
policies: Dict[str, Policy],
episode: Episode,
env_index: int,
**kwargs
):
# Make sure this episode is ongoing.
assert episode.length > 0, (
"ERROR: `on_episode_step()` callback should not be called right "
"after env reset!"
)
pole_angle = abs(episode.last_observation_for()[2])
raw_angle = abs(episode.last_raw_obs_for()[2])
assert pole_angle == raw_angle
episode.user_data["pole_angles"].append(pole_angle)
def on_episode_end(
self,
*,
worker: RolloutWorker,
base_env: BaseEnv,
policies: Dict[str, Policy],
episode: Episode,
env_index: int,
**kwargs
):
# Check if there are multiple episodes in a batch, i.e.
# "batch_mode": "truncate_episodes".
if worker.policy_config["batch_mode"] == "truncate_episodes":
# Make sure this episode is really done.
assert episode.batch_builder.policy_collectors["default_policy"].batches[
-1
]["dones"][-1], (
"ERROR: `on_episode_end()` should only be called "
"after episode is done!"
)
pole_angle = np.mean(episode.user_data["pole_angles"])
print(
"episode {} (env-idx={}) ended with length {} and pole "
"angles {}".format(
episode.episode_id, env_index, episode.length, pole_angle
)
)
episode.custom_metrics["pole_angle"] = pole_angle
episode.hist_data["pole_angles"] = episode.user_data["pole_angles"]
def on_sample_end(self, *, worker: RolloutWorker, samples: SampleBatch, **kwargs):
print("returned sample batch of size {}".format(samples.count))
def on_train_result(self, *, trainer, result: dict, **kwargs):
print(
"trainer.train() result: {} -> {} episodes".format(
trainer, result["episodes_this_iter"]
)
)
# you can mutate the result dict to add new fields to return
result["callback_ok"] = True
def on_learn_on_batch(
self, *, policy: Policy, train_batch: SampleBatch, result: dict, **kwargs
) -> None:
result["sum_actions_in_train_batch"] = np.sum(train_batch["actions"])
print(
"policy.learn_on_batch() result: {} -> sum actions: {}".format(
policy, result["sum_actions_in_train_batch"]
)
)
def on_postprocess_trajectory(
self,
*,
worker: RolloutWorker,
episode: Episode,
agent_id: str,
policy_id: str,
policies: Dict[str, Policy],
postprocessed_batch: SampleBatch,
original_batches: Dict[str, Tuple[Policy, SampleBatch]],
**kwargs
):
print("postprocessed {} steps".format(postprocessed_batch.count))
if "num_batches" not in episode.custom_metrics:
episode.custom_metrics["num_batches"] = 0
episode.custom_metrics["num_batches"] += 1
if __name__ == "__main__":
args = parser.parse_args()
ray.init()
trials = tune.run(
"PG",
stop={
"training_iteration": args.stop_iters,
},
config={
"env": "CartPole-v0",
"num_envs_per_worker": 2,
"callbacks": MyCallbacks,
"framework": args.framework,
# Use GPUs iff `RLLIB_NUM_GPUS` env var set to > 0.
"num_gpus": int(os.environ.get("RLLIB_NUM_GPUS", "0")),
},
callbacks=[WandbLoggerCallback(
name="test",
project="test",
**{"api_key_file": "~/.wandb"},
)],
).trials
```
### Issue Severity
Low: It annoys or frustrates me.