Hi,
I am using Helsinki-NLP/opus-mt-roa-en for translation and it takes about 3 mins to process a 10KB file. Most of the time is taken by model. generate() ,Using ray to see if parallel execution on mulitple cpu cores will decrease the execution time. Please find the code below:
@ray.remote
class RayTranslator(Translator):
pass @ray.remote
def translate_csr(translator, csr):
return translator.translate_csr(csr)
num_workers = 12
ray.init(ignore_reinit_error = True, logging_level=logging.ERROR, log_to_driver = False, num_cpus = num_workers)
start_time = time.time()
num_csrs, parallelism = 12, 12
csrs = [sentence_dict.copy() for _ in range(num_csrs)]
pool = ActorPool([RayTranslator.remote(tokenizer, model) for _ in range(parallelism)])
futures = pool.map(lambda actor, csr: actor.translate_csr.remote(csr), csrs)
translated_csrs, generation_times = zip(*futures)
print(f"Total time with ray for {num_csrs} CSRs with {parallelism} actors: {time.time() - start_time} "
f"including {sum(generation_times)/parallelism} sec generating the translation (model.generate call)")
ray.shutdown()
num_workers = 12
ray.init(ignore_reinit_error = True, logging_level=logging.ERROR, log_to_driver = False, num_cpus=num_workers)
translator = Translator(tokenizer, model)
start_time = time.time()
num_csrs= 12
csrs = [sentence_dict.copy() for _ in range(num_csrs)]
translated_csrs, generation_times = zip(*ray.get([translate_csr.remote(translator, csr) for csr in csrs]))
print(f"Total time with ray for {num_csrs} CSRs with {num_workers} workers: {time.time() - start_time} "
f"including {sum(generation_times)*num_csrs/num_workers**2} sec generating the translation "
f"(model.generate call)")
ray.shutdown()
Two concerns I am facing :
Scalability (it is 1/2 instead of 1/8th )
memory consumption is too high if each worker has a copy of the model instance. is there any way of having shared memory for model instances across different workers?
Can you elaborate more on the first point? What is the behavior you expect and what are you getting right now?
And for the second point, you can put the model into the object store once and then pass around the object reference to each Actor like so:
object_ref = ray.put(model)
Though wouldn’t you still need to actually load the model into the process memory on each worker? It seems like each worker needing a copy of the model instance is unavoidable.
Hey @amogkam, @Alex
Thank you for replying to the post.
My running time:
Total time without ray for 8csrs: 568.111
Total time with Ray for 8csrs with 8 actors: 257.83848
Total time with Ray for 8csrs with 8 workers: 260.8498
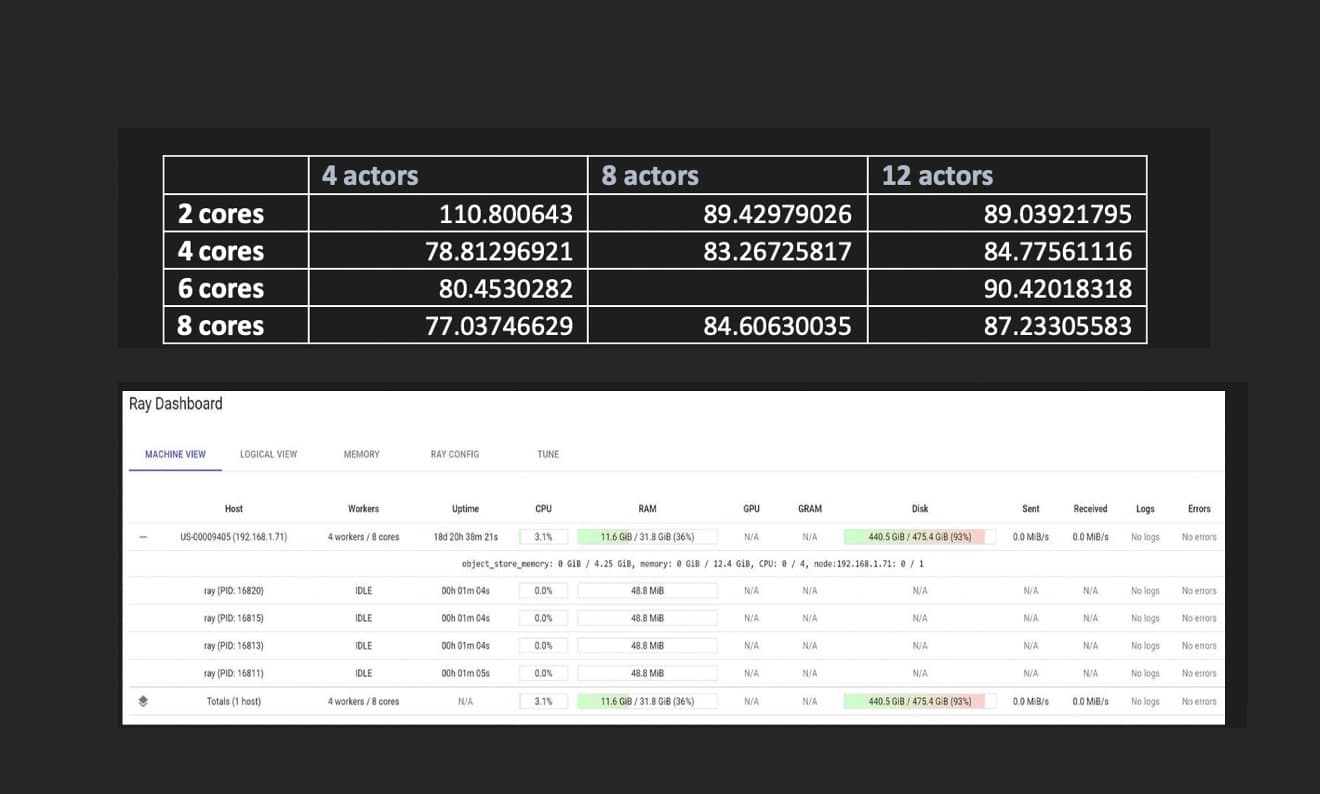
Given there are 8 cores on my machine, performance does not scale linearly, there is some parallelism, ideally expecting to see 1/8th time with Ray. How can I improve the scalability here?
I did try using ray.put() method. How do I know it is not creating multiple instances of model? (so, even when ray.put() is used it creates multiple instances of model ? )Memory footprint is almost similar or am I mistaken ?
model_id = ray.put(model)
tokenizer_id = ray.put(tokenizer)
ray.init(ignore_reinit_error = True, logging_level=logging.ERROR, log_to_driver = False)
start_time = time.time()
num_csrs, parallelism = 8, 12
csrs = [sentence_dict.copy() for _ in range(num_csrs)]
pool = ActorPool([RayTranslator.remote(tokenizer_id, model_id) for _ in range(parallelism)])
futures = pool.map(lambda actor, csr: actor.translate_csr.remote(csr), csrs)
translated_csrs, generation_times = zip(*futures)
print(f"Total time with ray for {num_csrs} CSRs with {parallelism} actors: {time.time() - start_time} "
f"including {sum(generation_times)/parallelism} sec generating the translation (model.generate call)")
ray.shutdown()
num_workers = 12
ray.init(ignore_reinit_error = True, logging_level=logging.ERROR, log_to_driver = False, num_cpus=num_workers)
translator = Translator(tokenizer, model)
translator_id = ray.put(translator)
start_time = time.time()
num_csrs= 8
csrs = [sentence_dict.copy() for _ in range(num_csrs)]
translated_csrs, generation_times = zip(*ray.get([translate_csr.remote(translator_id, csr) for csr in csrs]))
print(f"Total time with ray for {num_csrs} CSRs with {num_workers} workers: {time.time() - start_time} "
f"including {sum(generation_times)*num_csrs/num_workers**2} sec generating the translation "
f"(model.generate call)")
ray.shutdown()
Regarding scalability, the first thing I would try is to make sure that for a single model, the Ray implementation should have the same time as the non-Ray implementation.
If that is the case, then can you confirm that the 8 actors are actually running in parallel? You can do this by looking at the Ray dashboard or by simply doing a ps aux | grep RayTranslator to see the number of processes that are being run.
Also, I would do some more granular timing here. Can you separate the timing for Actor creation vs. actually executing the translation?
Regarding the memory- if you use ray.put() only one instance of the model will exist in the shared memory object store. However each actor/process still would have to copy and deserialize the model from the object store into its local in-process memory to actually use the object.
Hi @Alex,
No, I have tried with multiple nodes, for example: 2, 4, 6, 8. I am using pytorch model, I don’t think, it is multi-threaded(GIL in python makes multithreading impossible).
While this is more or less true for pure python applications, many libraries do get around this when they implement things in C/C++ (for example, if the underlying framework is pytorch, and you don’t explicitly limit the number of threads, it will use all of them).
When you use multiple nodes, are you able to check the dashboard and see if there’s actually any cpu utilization on the other nodes?
Are you able to see any CPU usage while the tasks are running? It looks like the job has finished in that screenshot. Also, are you able to use multiple nodes? Your model may already be using multiple threads on a single node.