Hello Team,
I am testing out DAG driver for creating parallel processing branches for one of our use-case.
The use-case is as follows:
- Base64 image comes as request
- Image is converted to proper input for model
- External api call (Azure ocr api) is performed in one deployment
- Object detector model (Detectron) is called in another deployment.
I have implemented the functionality using deployments and DAGdriver. Although functionally it has been working as expected. I was seeing a constant memory increase for continuous requests.
In order to investigate properly, I converted my processing deployments (AzureAPI call and Detectron model inference) into simple functions which just return a dictionary or arrays.
DetectronDeployment
@serve.deployment()
class DetectronDeployment:
def __init__(self):
self.doc_detector = ObjDetector(MODEL_CFG)
self.doc_processor = DocDetector(640, 640)
async def detect_doc(self, file_bytes):
start_time = time.time()
image_np = np.frombuffer(file_bytes, np.uint8)
img = cv2.imdecode(image_np, flags=1)
try:
img_scaler = self.doc_processor.standardise_img(img)
detections = self.doc_detector.get_pred(self.doc_processor.final_img)
except Exception as ex:
log.error(ex)
log.error(traceback.print_exc())
filter_detections = []
for i in range(len(detections)):
filter_detections.append(
{
"doc_type": self.doc_detector.classes[
detections.pred_classes[i].item()
],
"confidence": detections.scores[i].item(),
"bbox": self.doc_processor.process_bbox(detections.pred_boxes[i]),
}
)
log.info("Time taken for detections :: {}".format(time.time() - start_time))
scale_params = self.doc_processor.export_params()
return json.dumps([scale_params, filter_detections])
async def forward(self,uploaded_file):
start_time = time.time()
resp = {
"detection values":[1,2,3,4,5]
}
# resp = await self.detect_doc(uploaded_file)
log.info("Time taken to analyze image :: {}".format(time.time() - start_time))
return resp
detectron_deployment = DetectronDeployment.bind()
AzureDeployment
@serve.deployment()
class AzureDeployment:
def __init__(self):
self.ocr_api = AzureAPI(os.environ.get("SUBKEY"), os.environ.get("AZURE_ENDPOINT"))
def forward(self,uploaded_file):
start_time = time.time()
time.sleep(0.2)
# resp = self.ocr_api.analyze_image(uploaded_file)
resp = {
"status": "success",
"status_code": 200,
"result": {
"extracted_data": {
"aadhaarNumber": "567420078076",
"dob": " 08/01/1991",
"gender": "Male",
"name": "Purushothama",
"fatherName": "NA",
"address": "NA",
"docType": "aadhar front half"
},
"image_quality": {
"blur": 0,
"res": 0.05
}
},
"version": "1.2"
}
log.info("Time taken to analyze image :: {}".format(time.time() - start_time))
return resp
azure_deployment = AzureDeployment.bind()
As you can see both the deployments contain a forward function which basically does nothing more than returning an array and a json respectively
My DAGDriver graph is defined in this way
with InputNode() as input_file:
print(f"input file is :: {input_file}")
health_response = health_deployment.forward.bind()
dag = aggregate.bind(azure_deployment.forward.bind(input_file),detectron_deployment.forward.bind(input_file))
serve_dag = DAGDriver.options(num_replicas=1).bind({
"/process":dag,
"/health": health_response
})
Here is health_deployment is →
@serve.deployment()
class HealthDeployment():
async def forward(self) -> str:
return "Server is healthy"
If you look at the screenshots below, you will find that that though the object store memory and the memory utilised per Deployment is constant, but still the DAGDriver replica linearly increases with the requests coming in
Timestamp 1

Timestamp 2
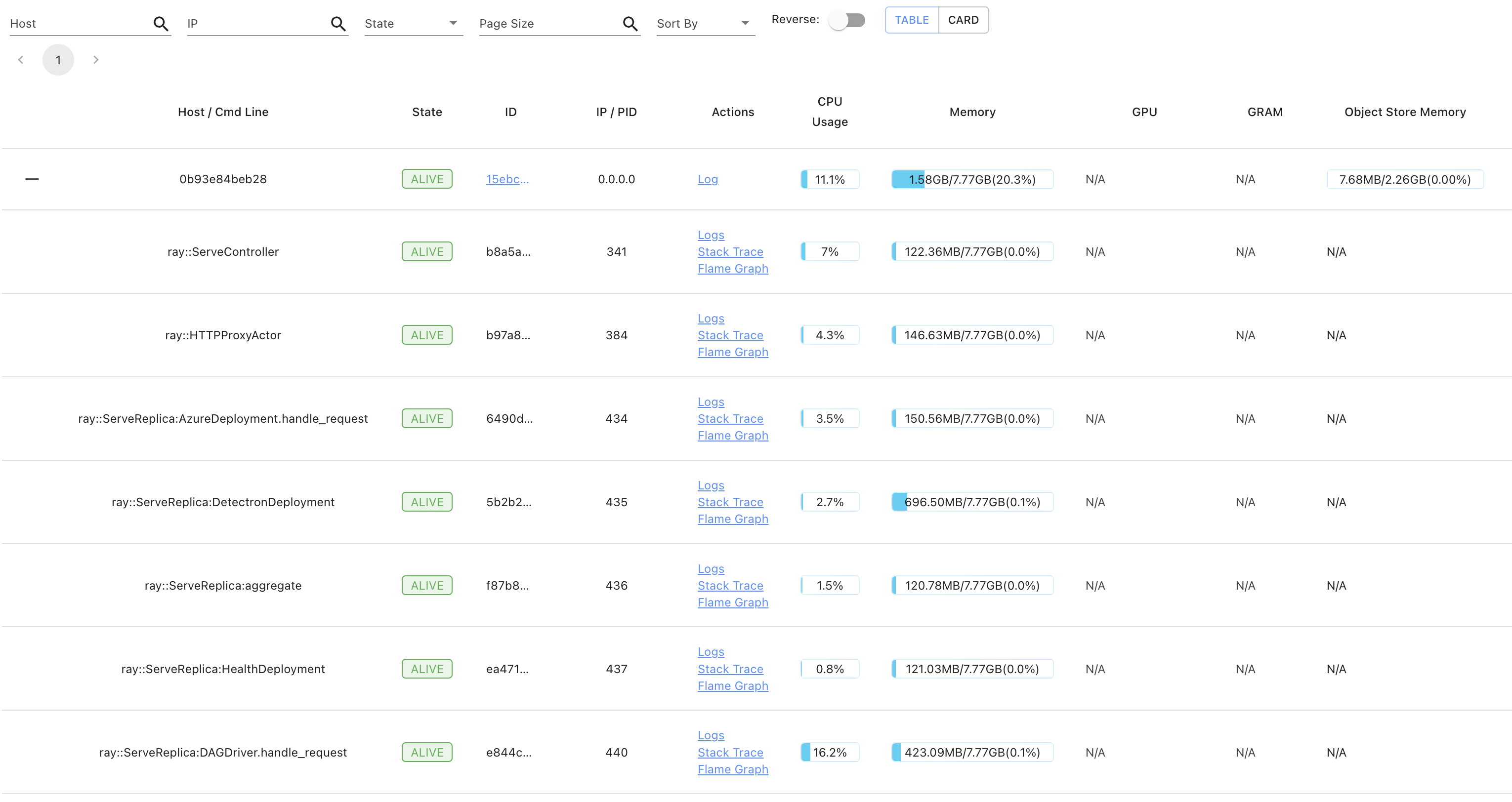
Timestamp 3

Timestamp 4
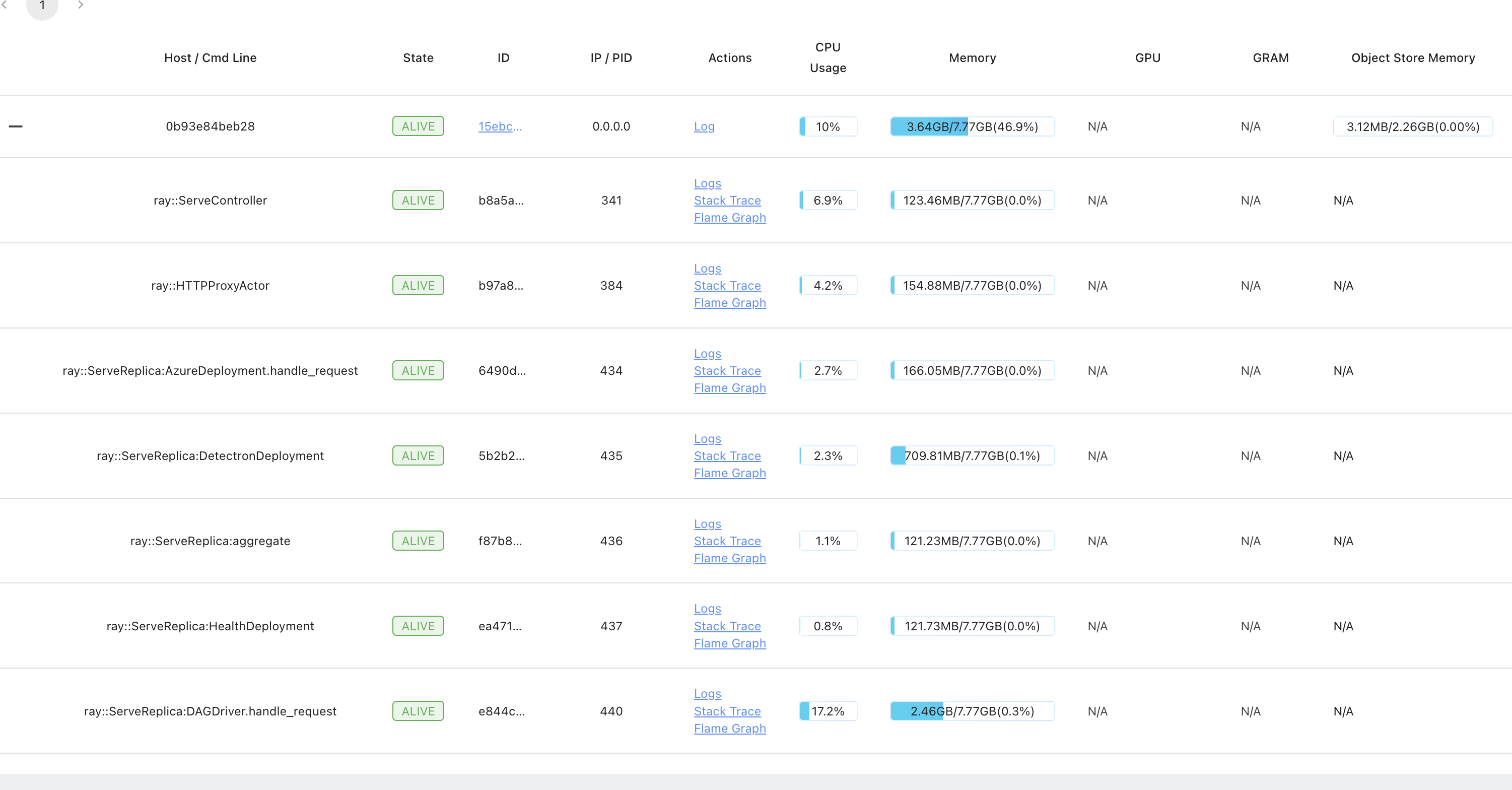
Kindly have a look at this and let me know if I am doing something wrong here with my deployments and request flow