I am wondering what the intended architecture should look like when using ppo with vf_share_layers = False and an lstm. Based on the comment in the ppo config and reading the documentation I would have thought that if it is set to false then there would be no sharing of the layers above the lstm.
When I was looking at the LSTMWrapper code I realized that they would be sharing those layers even when vf_share_layers=False.
Here is a picture of the network with use_lstm=False. To make it more clear I have add 3 to the size of the _value_branch_separate model. As you can see they are not shared. The policy is on the left (size 256) and the vf is on the right (size 259).
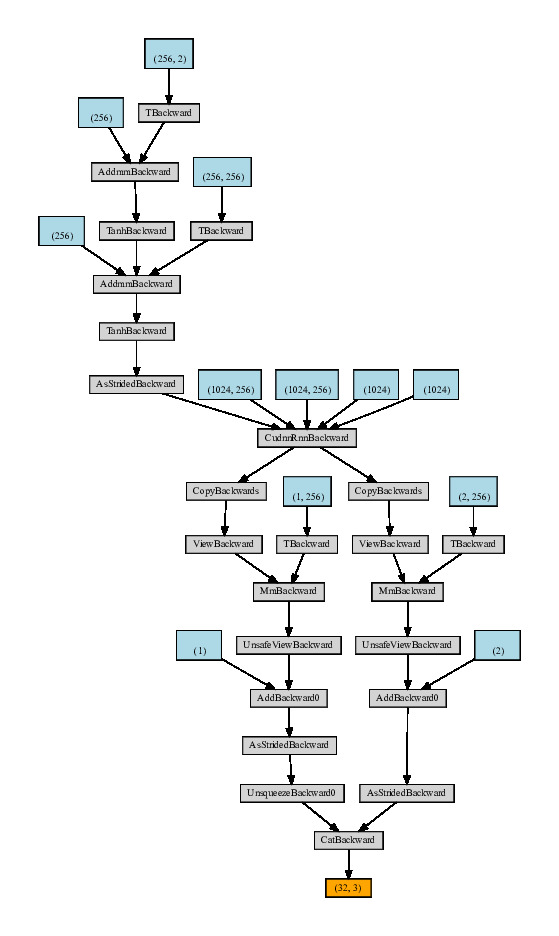
Here is a picture of the network with use_lstm=True. As you can see in this one the layers going into the lstm are shared. I could not get the order the same so in this case the value function is on the left and the policy is on the right.
Hey @mannyv , thanks for raising this. It’s indeed a bug. When wrapping your vf_share_layers=False model with an LSTM, all layers will be shared and the setting is ignored.
I’ll create an issue and provide a fix.
Thinking about this more, this would actually take a lot of changes to make this work:
our Models have a separate value_function method, which would - in this case - also have to take a state input list (it currently doesn’t).
the LSTM wrapper would need to know about the “location” of the separate value branch in the wrapped model (as it would have to call that branch separately). This would be ok for default models (under RLlib’s own control), but would become quite difficult for custom models.
I’m suggesting for now, you create a custom LSTM model that contains all required LSTM elements and specify that custom model in your config.
We are working on making the ModelV2 API simpler (or actually not needing it anymore at all). Instead, users will be able to register any number of models with the policy (e.g. “policy_model” and “value_model” and then call these directly in the algos). This is WIP, though.
@sven1977 Hi Sven, I think this is still an open issue, right? So if I want to use separate branches for value and actor networks I would have to write a custom model, correct?
@mannyv Very good model architecture visualization. I have done some investigation work but experiments on rllib met problem with framework(‘torch’). It seems like you used torchviz to do visualization, right? Could you share some information about how to do this? Thanks a lot.
# Provide dummy state inputs if not an RNN (torch cannot jit with
# returned empty internal states list).
policy._lazy_tensor_dict(policy._dummy_batch)
if "state_in_0" not in policy._dummy_batch:
policy._dummy_batch["state_in_0"] = policy._dummy_batch[
SampleBatch.SEQ_LENS
] = np.array([1.0])
seq_lens = policy._dummy_batch[SampleBatch.SEQ_LENS]
state_ins = []
i = 0
while "state_in_{}".format(i) in policy._dummy_batch:
state_ins.append(policy._dummy_batch["state_in_{}".format(i)])
i += 1
mod = torch.jit.trace(policy.model, dummy_inputs)
filename = os.path.join(export_dir, "torchscript_model.pt")