Hello Ray Team,
After I train PPO model (with LSTM_Use == True) and try to evaluate model using “compute_actions method” and “compute_single_action method” I get error as follows
ValueError: Must pass in RNN state batches for placeholders [<tf.Tensor ‘default_policy/Placeholder:0’ shape=(?, 256) dtype=float32>, <tf.Tensor ‘default_policy/Placeholder_1:0’ shape=(?, 256) dtype=float32>], got []
I’m not sure how do I input the argument in required parameter of compute_actions method or compute_single_action method. Normally, when I use PPO without LSTM , I simply add argument like this
current_state = array([10., 5., 1., 2., 4., 2., 1., 5., 3., 5., 3., 4., 1., 5., 4., 4., 0.])
action = policy.compute_single_action(current_state ,state=[])
My Environment
OS: Windows 10
Python: 3.7.4
Tensorflow: 2.1.0
Numpy:1.18.5
Ray:1.0.0
My PPO Config:
{‘num_workers’: 2,
‘num_envs_per_worker’: 1,
‘rollout_fragment_length’: 200,
‘batch_mode’: ‘truncate_episodes’,
‘num_gpus’: 1,
‘train_batch_size’: 5000,
‘model’: {‘fcnet_hiddens’: [256, 256],
‘fcnet_activation’: ‘elu’,
‘conv_filters’: None,
‘conv_activation’: ‘elu’,
‘free_log_std’: False,
‘no_final_linear’: False,
‘vf_share_layers’: True,
‘use_lstm’: True,
‘max_seq_len’: 20,
‘lstm_cell_size’: 256,
‘lstm_use_prev_action_reward’: False,
‘_time_major’: False,
‘framestack’: False,
‘dim’: 84,
‘grayscale’: False,
‘zero_mean’: True,
‘custom_model’: None,
‘custom_model_config’: {},
‘custom_action_dist’: None,
‘custom_preprocessor’: None},
‘optimizer’: {},
‘gamma’: 0.99,
‘horizon’: None,
‘soft_horizon’: False,
‘no_done_at_end’: False,
‘env_config’: {},
‘env’: ‘SimpleSupplyChain’,
‘normalize_actions’: False,
‘clip_rewards’: True,
‘clip_actions’: True,
‘preprocessor_pref’: ‘deepmind’,
‘lr’: 5e-05,
‘monitor’: False,
‘log_level’: ‘WARN’,
‘callbacks’: ray.rllib.agents.callbacks.DefaultCallbacks,
‘ignore_worker_failures’: False,
‘log_sys_usage’: True,
‘fake_sampler’: False,
‘framework’: ‘tf’,
‘eager_tracing’: False,
‘no_eager_on_workers’: False,
‘explore’: True,
‘exploration_config’: {‘type’: ‘StochasticSampling’},
‘evaluation_interval’: None,
‘evaluation_num_episodes’: 10,
‘in_evaluation’: False,
‘evaluation_config’: {},
‘evaluation_num_workers’: 0,
‘custom_eval_function’: None,
‘sample_async’: False,
‘_use_trajectory_view_api’: False,
‘observation_filter’: ‘NoFilter’,
‘synchronize_filters’: True,
‘tf_session_args’: {‘intra_op_parallelism_threads’: 8,
‘inter_op_parallelism_threads’: 8,
‘gpu_options’: {‘allow_growth’: True},
‘log_device_placement’: False,
‘device_count’: {‘CPU’: 1},
‘allow_soft_placement’: True},
‘local_tf_session_args’: {‘intra_op_parallelism_threads’: 8,
‘inter_op_parallelism_threads’: 8},
‘compress_observations’: False,
‘collect_metrics_timeout’: 180,
‘metrics_smoothing_episodes’: 100,
‘remote_worker_envs’: False,
‘remote_env_batch_wait_ms’: 0,
‘min_iter_time_s’: 0,
‘timesteps_per_iteration’: 0,
‘seed’: None,
‘extra_python_environs_for_driver’: {},
‘extra_python_environs_for_worker’: {},
‘num_cpus_per_worker’: 1,
‘num_gpus_per_worker’: 0,
‘custom_resources_per_worker’: {},
‘num_cpus_for_driver’: 1,
‘memory’: 0,
‘object_store_memory’: 0,
‘memory_per_worker’: 0,
‘object_store_memory_per_worker’: 0,
‘input’: ‘sampler’,
‘input_evaluation’: [‘is’, ‘wis’],
‘postprocess_inputs’: False,
‘shuffle_buffer_size’: 0,
‘output’: None,
‘output_compress_columns’: [‘obs’, ‘new_obs’],
‘output_max_file_size’: 67108864,
‘multiagent’: {‘policies’: {},
‘policy_mapping_fn’: None,
‘policies_to_train’: None,
‘observation_fn’: None,
‘replay_mode’: ‘independent’},
‘logger_config’: None,
‘replay_sequence_length’: 1,
‘use_critic’: True,
‘use_gae’: True,
‘lambda’: 0.95,
‘kl_coeff’: 0.5,
‘sgd_minibatch_size’: 500,
‘shuffle_sequences’: True,
‘num_sgd_iter’: 10,
‘lr_schedule’: None,
‘vf_share_layers’: True,
‘vf_loss_coeff’: 1.0,
‘entropy_coeff’: 0.01,
‘entropy_coeff_schedule’: None,
‘clip_param’: 0.1,
‘vf_clip_param’: 1000000,
‘grad_clip’: None,
‘kl_target’: 0.01,
‘simple_optimizer’: False,
‘_fake_gpus’: False,
‘worker_index’: 0}
My Summary Model:

How do I input the parameter in Compute_action method and Compute_single_action method?
Do I need to reshape my input size? What shape size do I need to reshape to?
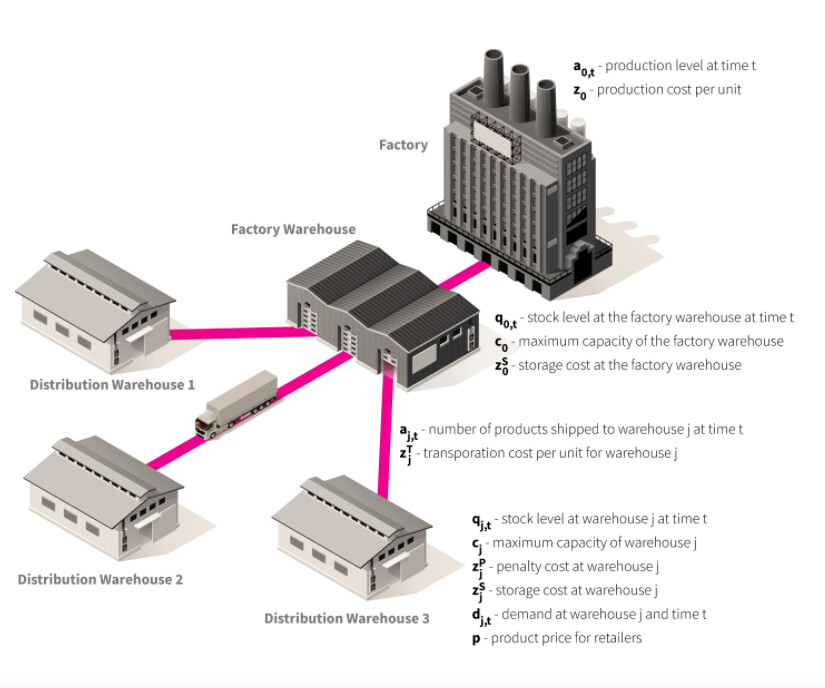
P.S. I create custom Supply Chain Environment in Gym
Thank you
Pond