1. Severity of the issue: (select one)
None: I’m just curious or want clarification.
Low: Annoying but doesn’t hinder my work.
Medium: Significantly affects my productivity but can find a workaround.
High: Completely blocks me.
2. Environment:
Ray version: ray[all]==2.52.0
Python version: 3.12.7
OS: Amazon Linux
Cloud/Infrastructure: AWS
3. What happened vs. what you expected:
I am very new to this cloud stuff, so be kind to me!
After a week of reading fiddling and coding I have a ray compute cluster running, which is awesome.
I run 4 CPU nodes and 2 GPU nodes, all of those nodes have a lot of ram (500gb and 300gb) but only a very small gp3 drive attached (100gb)
I first thougth that the object store will be distributed over all the RAM in the nodes, so did not think I will need much space for spilling. It seams I misunderstood here, sadly.
I work with pointclouds with billions of points, so calculations sometimes lead to some serious spilling.
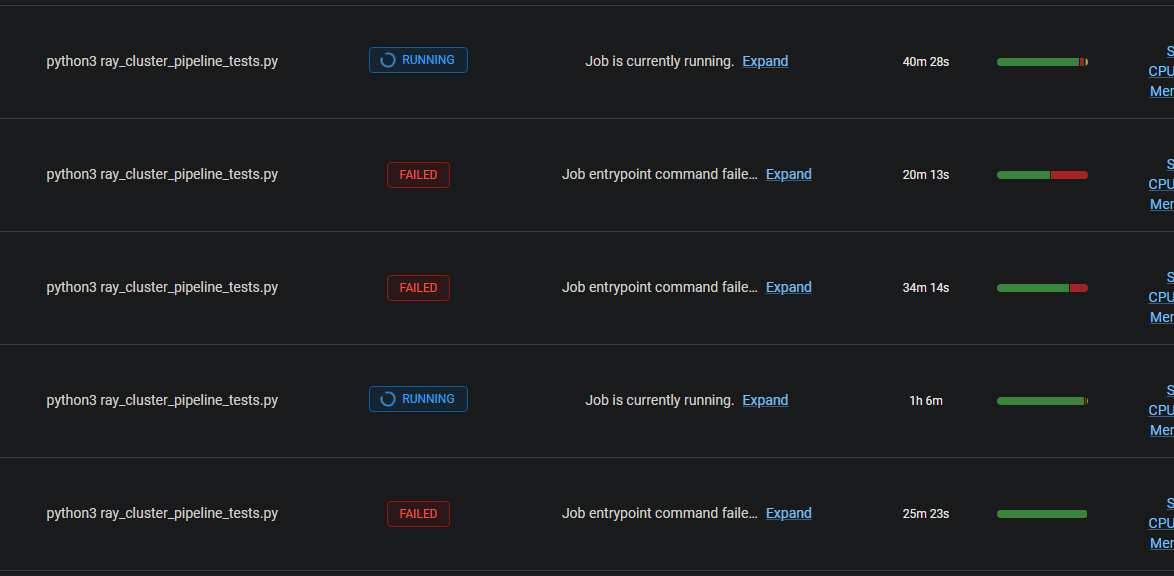
I now wanted to stress test the cluster, and started 5 jobs at once. At some point a drive of a node ran full and jobs started to die.
Most remote calls in the pipeline do not (yet) tell ray any resource needs, so it makes sense that stuff explodes, i was expecting that.
Now from the 5 jobs, 3 died and 2 are completely stuck as it seams.
The drives of 2 nodes are still full to the brim, so no data from failed jobs were deleted I believe.
Both ‘running’ jobs have a bunch of tasks ‘PENDING_NODE_ASSIGNMENT’ but are never assigned. the tasks all just have a resource need of 1 CPU.
In the overview the cluster shows resource status 43.0/384.0 CPU, so I am unsure why the tasks are not assigned?
So my questions; why is the spilled data of failed jobs not deleted?
Why are the tasks not assigned to nodes?
The spilled data from failed jobs is not automatically deleted because Ray does not currently implement disk-specific load balancing or automatic cleanup of spilled objects when jobs fail; spilled objects remain until their references are explicitly released or the node is restarted. This can lead to nodes running out of disk space, which in turn blocks new tasks from being scheduled, even if there are available CPUs, because Ray cannot create new objects or spill further when the disk is full. This behavior is confirmed in both user reports and Ray’s documentation, which note that Ray does not rebalance or clean up spilled objects across nodes and that disk pressure can block task scheduling even if other resources are available (e9bfd7ea, b6198811, 159bc4bb).
Tasks remain in the PENDING_NODE_ASSIGNMENT state because, with the disk full, Ray cannot create or spill new objects required for task execution, effectively blocking scheduling on those nodes. Even if CPUs are available, Ray’s scheduler will not assign tasks if the node cannot handle object creation due to disk pressure (b6198811, e9bfd7ea). To resolve this, you should manually clean up the spill directories on the affected nodes or restart the nodes to free up disk space. For future runs, consider increasing disk size or tuning your workload to reduce object store and spill usage.
Would you like more detail on how to monitor or clean up spilled objects, or on configuring Ray to better handle large workloads?
@RunLLM
I see. I guess that makes sense but is also quite a big problem.
So for production use we have to be very careful that this never happens, because if it does the whole cluster stops functioning and cant recover by itself?
This seams like a scary situation. When customer data that we dont have full control over start pouring in we wil have a hard time making the cluster robust.
You said that nothing is deleted from the object store if there is still something referenceing it. but after a job failed, is there anythiung left referencing it? Is the failed job still ‘there’ somehow ‘alive’ and keeping references?
I would think a failed job is dead and killed, so it cant hold any references anymore
Yes, this is a significant operational risk: if spilled objects are not cleaned up and disk fills up, the cluster can become stuck and will not recover automatically—manual intervention is required (e9bfd7ea, b6198811). After a job fails, in most cases, its references should be released, but Ray sometimes retains references if the driver or actors do not exit cleanly, or if there are lingering references in other jobs or detached actors (56930687). This can prevent spilled objects from being deleted, especially if the job did not shut down gracefully.
If the job is truly dead and all references are gone, the objects should eventually be cleaned up, but in practice, leaks or stuck references can occur, especially in complex or error-prone workloads (56930687). This is why Ray clusters in production need careful monitoring and sometimes custom cleanup logic.
Would you like more detail on how to monitor for lingering references or best practices for robust production deployments?
@RunLLM
Oh well damn. I was wishing for the cluster to be the holy grail solution to our issues, but I am less confident now.
So to mitigate this issue we need enough space to spill on every node. Which will get unnecessary expensive quite fast probably, especically because most nodes will not need the space most of the time. just some odd circumstances will lead to such issues.
It would really be good if this spilling could also be distributed, like using the drive of another node.
If I remember correctly it is possible to define multliple spill paths, that are used after one another. So we could get a little super fast drive for every node, and then as a fallback something huge and slow, maybe even shared between the nodes?
Anyway, what can I do in a production environment to make this more robust, clean up dead jobs, and fight lingering references.
Leaking cant be allowed in a system that should stay running.
It seems likely that your concerns are valid: Ray currently does not support distributing spill files across nodes or using remote/shared disks for object spilling—spilling is always local to each node (e9bfd7ea, b6198811). While you can configure multiple spill paths per node, Ray will only use them sequentially on that node, not across the cluster. Using a large, shared network file system (like NFS or EFS) as a spill path is technically possible, but not officially recommended due to potential performance and consistency issues (95961ebc).
For production robustness, you should:
Monitor disk usage and object store memory closely.
Use Ray’s dashboard and tools like ray memory to detect lingering references and leaks.
Ensure jobs and actors exit cleanly, and consider implementing periodic cleanup scripts for spill directories.
Consider using larger disks or auto-scaling policies to add nodes before disk pressure becomes critical.
For long-running clusters, periodically restart nodes or the cluster to clear out any leaked objects (56930687).
Would you like more detail on configuring spill paths, monitoring, or automated cleanup strategies?
When attached to the cluster I can see that no actor or task is left alive (except _stats_actor)
There are still 4 pinned objects though that should probably not be there?
Table (group by class):
------------------------------------
CLASS_NAME STATE_COUNTS
0 JobSupervisor DEAD: 5
1 RemoteContextStore DEAD: 1
2 _StatsActor ALIVE: 1
root@ip-172-31-11-111:/app# ray summary tasks
2025-12-02 14:39:08,219 INFO api.py:68 -- (3.75 / 30 seconds) Waiting for the response from the API server address http://172.31.11.111:8265/api/v0/tasks/summarize.
======== Tasks Summary: 2025-12-02 14:39:11.454628 ========
Stats:
------------------------------------
total_actor_scheduled: 0
total_actor_tasks: 1031
total_tasks: 8969
Table (group by func_name):
------------------------------------
FUNC_OR_CLASS_NAME STATE_COUNTS TYPE
0 unpack_node FAILED: 24 NORMAL_TASK
FINISHED: 8943
1 _StatsActor.get_datasets FINISHED: 203 ACTOR_TASK
2 RemoteContextStore.get_all FINISHED: 827 ACTOR_TASK
3 reduce_partitions FINISHED: 1 NORMAL_TASK
4 RemoteContextStore.set_many FINISHED: 1 ACTOR_TASK
5 download_dataset FINISHED: 1 NORMAL_TASK
root@ip-172-31-11-111:/app# ray list objects
======== List: 2025-12-02 14:43:53.449378 ========
Stats:
------------------------------
Total: 4
Table:
------------------------------
OBJECT_ID OBJECT_SIZE TASK_STATUS ATTEMPT_NUMBER REFERENCE_TYPE CALL_SITE TYPE PID IP
0 006fadbbb879c3b0ffffffffffffffffffffffff0500000002e1f505 807.000 B NIL 1 PINNED_IN_MEMORY (deserialize task arg) downloader.src.unpacking_worker.unpack_node WORKER 256089 172.31.0.25
1 006fadbbb879c3b0ffffffffffffffffffffffff0500000003e1f505 351.000 B NIL 1 PINNED_IN_MEMORY (deserialize task arg) downloader.src.unpacking_worker.unpack_node WORKER 256089 172.31.0.25
2 006fadbbb879c3b0ffffffffffffffffffffffff0500000004e1f505 10.000 B NIL 1 PINNED_IN_MEMORY (deserialize task arg) downloader.src.unpacking_worker.unpack_node WORKER 256089 172.31.0.25
3 006fadbbb879c3b0ffffffffffffffffffffffff05000000b108f605 386.284 KiB NIL 1 PINNED_IN_MEMORY (deserialize task arg) downloader.src.unpacking_worker.unpack_node WORKER 256089 172.31.0.25
Still, the tmp is not cleaned out. Also the cluster is not downscaling, even though no work has been done in quite some time
The 4 “PINNED_IN_MEMORY” objects remain because the worker process (PID 256089) still holds deserialized references to them, even though all actors and tasks are dead. In Ray, objects are only released from the object store when all references—including those in worker memory—are gone. If a worker process does not exit cleanly or leaks references, these objects can remain pinned, preventing cleanup and blocking cluster downscaling (ba752da8, 624d3d09).
To resolve this, ensure the worker process (PID 256089) is terminated or restarts, which should release the references and allow Ray to clean up the objects and downscale the cluster. If the process is stuck, you may need to kill it manually. For robust production use, monitor for lingering worker processes and automate cleanup if necessary.
Would you like more detail on how to automate detection and cleanup of such leaks?
But why is the worker not killed if there is no work left?
Also looking in the cluster I see that the Disks are still full, multiple hundred GB, so its not those objects..?
In the dashboard I see on one node that it says WORKER (2) sadly the dashboard crashes when i click on that tab. So unsure whatsup with that.
how can it happen that workers get stuck like this?
This is one of the machines with completely full disk, only 20kb free. This might have broken things?
If a worker is not killed even when there is no work left, it is often due to Ray’s autoscaler or resource manager not detecting the node as idle—this can happen if there are lingering references, stuck processes, or if the node is under disk pressure. When a node’s disk is completely full, Ray may be unable to write logs, update state, or clean up spill files, which can cause both the autoscaler and the dashboard to malfunction or hang (e9bfd7ea, b6198811). Stuck workers can occur if they are waiting for resources, blocked on I/O, or if the node is in a broken state due to full disk.
In this situation, the full disk likely prevents Ray from cleaning up, updating its state, or terminating workers properly. Manual intervention is required: free up disk space by deleting old spill files or logs, and consider restarting the affected node(s) to restore normal operation (e9bfd7ea).
Would you like step-by-step instructions for cleaning up disk space and recovering the cluster?
You’re correct—simply adding more storage may only delay the problem if the underlying causes (object leaks, unbounded spilling, or lack of cleanup) aren’t addressed. The best practice is to size storage so that the working set and expected spill volume fit comfortably, but also to monitor and control memory usage, spill rates, and reference lifetimes (ba752da8, 7094df69).
For robust production, combine increased storage with:
Monitoring object store and disk usage.
Limiting the number of concurrent jobs/tasks.
Ensuring all references are released after job completion.
Periodic cleanup or node restarts to clear leaks.
Would you like more detail on how to estimate storage needs or set up monitoring and cleanup?