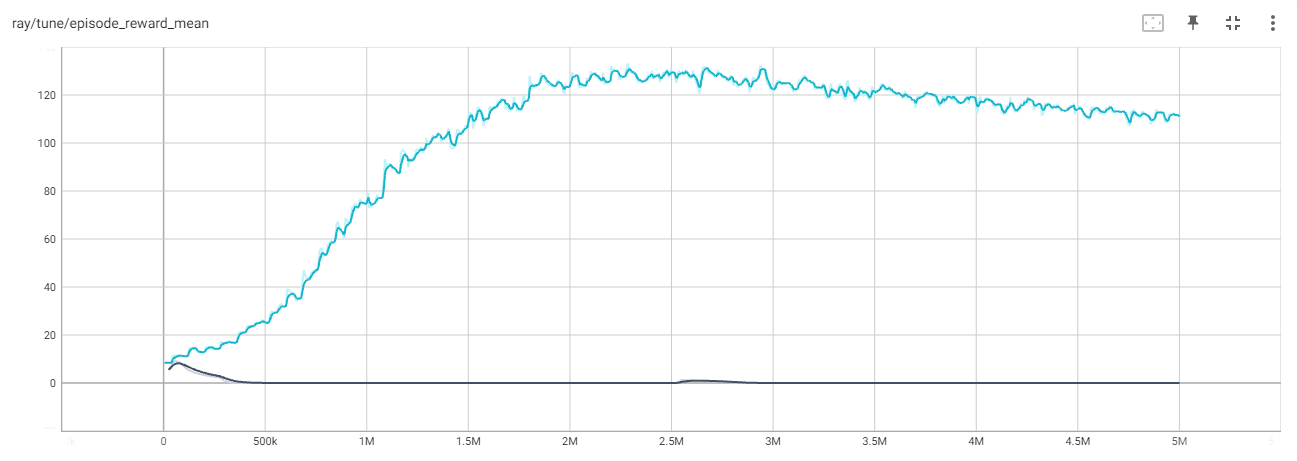
Hi @arturn ,
I’m using an external simulator which plugs into the policy client / server objects. The code for the client and the server are below. If it’s just a case of hyperparameter tuning then that’s great as I was expecting to do so anyway I just wanted to get a baseline using the default configs. My worry is that something else is going wrong.
Client:
from ray.rllib.env.policy_client import PolicyClient
from AcEnv import AcEnv
IP = "<REDACTED>"
PORT = 29200
ADDR = (IP, PORT)
SIZE = 1024
FORMAT = "utf-8"
def main(car_num, port, address="localhost", inference_mode="local", no_train=False, off_policy=False, stop_reward=9999):
env = AcEnv(car_num, IP, PORT, SIZE, FORMAT)
client = PolicyClient(
f"http://{address}:{port}", inference_mode=inference_mode
)
# Start a new episode.
obs = env.reset()
eid = client.start_episode(training_enabled=not no_train)
step_count = 1
rewards = 0.0
reward_list = []
while True:
# Compute an action randomly (off-policy) and log it.
if off_policy:
action = env.action_space.sample()
client.log_action(eid, obs, action)
# Compute an action locally or remotely (on server).
# No need to log it here as the action
else:
action = client.get_action(eid, obs)
step_count += 1
# Perform a step in the external simulator (env).
obs, reward, done, info = env.step(action)
rewards += reward
reward_list.append(reward)
# Log next-obs, rewards, and infos.
client.log_returns(eid, reward, info=info)
# if step_count % 10 == 0: # For debugging the new feature space
# print()
# print()
# print(obs)
# Reset the episode if done.
if done or step_count >= 660: # Around 1 minute
#print("Total reward:", rewards)
if rewards >= stop_reward:
#print("Target reward achieved, exiting")
exit(0)
rewards = 0.0
step_count = 0
#print(f"###################Car {car_num}###########################")
#print(f"Reward list: {reward_list}")
#print(f"################End of Car {car_num}#######################")
# End the old episode.
client.end_episode(eid, obs)
# Start a new episode.
obs = env.reset()
eid = client.start_episode(training_enabled=not no_train)
Server:
from __future__ import division
import argparse
from math import floor
import os
import numpy as np
import ray
from gymnasium.spaces import Box
from ray import air, tune
from ray.rllib.algorithms import AlgorithmConfig
from ray.rllib.algorithms.ppo import PPOConfig
from ray.rllib.algorithms.registry import get_algorithm_class
from ray.rllib.algorithms.sac import SACConfig
from ray.rllib.env.policy_server_input import PolicyServerInput
from ray.rllib.algorithms.callbacks import DefaultCallbacks
from ray.rllib.evaluation import Episode, RolloutWorker
from ray.rllib.policy import Policy
from ray.rllib.policy.sample_batch import SampleBatch
from typing import Dict, Tuple
from ray.tune.registry import get_trainable_cls
SERVER_ADDRESS = "localhost"
# In this example, the user can run the policy server with
# n workers, opening up listen ports 9900 - 990n (n = num_workers - 1)
# to each of which different clients may connect.
SERVER_BASE_PORT = 9900 # + worker-idx - 1
CHECKPOINT_FILE = "last_checkpoint_{}.out"
class CustomCallbacks(DefaultCallbacks):
def on_postprocess_trajectory(
self,
*,
worker: RolloutWorker,
episode: Episode,
agent_id: str,
policy_id: str,
policies: Dict[str, Policy],
postprocessed_batch: SampleBatch,
original_batches: Dict[str, Tuple[Policy, SampleBatch]],
**kwargs
) -> None:
# print("Starting custom callback")
# Set reward for each step to the reward of the next step.#
for i in range(len(postprocessed_batch["rewards"]) -1):
# print(postprocessed_batch["rewards"][i])
postprocessed_batch["rewards"][i] = postprocessed_batch["rewards"][i + 1]
def get_cli_args():
"""Create CLI parser and return parsed arguments"""
parser = argparse.ArgumentParser()
# Example-specific args.
parser.add_argument(
"--port",
type=int,
default=SERVER_BASE_PORT,
help="The base-port to use (on localhost). " f"Default is {SERVER_BASE_PORT}.",
)
parser.add_argument("--log-level", type=int, default=30)
parser.add_argument("--verbose", type=int, default=0, help="Verbose mode.")
parser.add_argument(
"--callbacks-verbose",
action="store_true",
help="Activates info-messages for different events on "
"server/client (episode steps, postprocessing, etc..).",
)
parser.add_argument(
"--num-workers",
type=int,
default=4,
help="The number of workers to use. Each worker will create "
"its own listening socket for incoming experiences.",
)
parser.add_argument(
"--no-restore",
action="store_true",
help="Do not restore from a previously saved checkpoint (location of "
"which is saved in `last_checkpoint_[algo-name].out`).",
)
# General args.
parser.add_argument(
"--run",
default="PPO",
choices=["SAC", "TD3", "APEX_DDPG", "PPO", "APPO", "A2C", "A3C"], # Add the rest here
help="The RLlib-registered algorithm to use.",
)
parser.add_argument("--layer-size", type=int, default=0)
parser.add_argument("--layer-count", type=int, default=0)
parser.add_argument("--n-step", type=int, default=1)
parser.add_argument("--num-cpus", type=int, default=4)
parser.add_argument("--num-cpus-for-local", type=int, default=1)
parser.add_argument("--num-gpus", type=int, default=1)
parser.add_argument("--num-gpus-per-worker", type=float, default=0)
parser.add_argument(
"--framework",
choices=["tf", "tf2", "torch"],
default="tf",
help="The DL framework specifier.",
)
parser.add_argument(
"--use-lstm",
action="store_true",
help="Whether to auto-wrap the model with an LSTM. Only valid option for "
"--run=[IMPALA|PPO|R2D2]",
)
parser.add_argument(
"--stop-iters", type=int, default=99999, help="Number of iterations to train."
)
parser.add_argument(
"--stop-timesteps",
type=int,
default=1000000,
help="Number of timesteps to train.",
)
parser.add_argument(
"--stop-reward",
type=float,
default=99999.9,
help="Reward at which we stop training.",
)
parser.add_argument(
"--as-test",
action="store_true",
help="Whether this script should be run as a test: --stop-reward must "
"be achieved within --stop-timesteps AND --stop-iters.",
)
parser.add_argument(
"--no-tune",
action="store_true",
help="Run without Tune using a manual train loop instead. Here,"
"there is no TensorBoard support.",
)
parser.add_argument(
"--local-mode",
action="store_true",
help="Init Ray in local mode for easier debugging.",
)
args = parser.parse_args()
print(f"Running with following CLI args: {args}")
return args
if __name__ == "__main__":
args = get_cli_args()
ray.init(log_to_driver=False, logging_level=args.log_level)
# `InputReader` generator (returns None if no input reader is needed on
# the respective worker).
def _input(ioctx):
# We are remote worker or we are local worker with num_workers=0:
# Create a PolicyServerInput.
if ioctx.worker_index > 0 or ioctx.worker.num_workers == 0:
return PolicyServerInput(
ioctx,
SERVER_ADDRESS,
args.port + ioctx.worker_index - (1 if ioctx.worker_index > 0 else 0),
)
# No InputReader (PolicyServerInput) needed.
else:
return None
# Algorithm config. Note that this config is sent to the client only in case
# the client needs to create its own policy copy for local inference.
config = get_trainable_cls(args.run).get_default_config()
# if args.num_cpus_for_local <= 0 or args.num_cpus_for_local > args.num_cpus:
# raise ValueError(
# "num_cpus_for_local must be > 0 and <= num_cpus: "
# f"{args.num_cpus_for_local} vs. {args.num_cpus}"
# )
if args.num_workers > 0:
worker_cpus = args.num_cpus / (args.num_workers + 1)
if worker_cpus > 1:
worker_cpus = floor(worker_cpus)
else:
worker_cpus = args.num_cpus
(config
# Indicate that the Algorithm we setup here doesn't need an actual env.
# Allow spaces to be determined by user (see below).
.environment(
env=None,
observation_space=Box(
np.array(
(([-1e3] * 6) + ([-1.] * 3)) * 40 + [-np.inf] * 3 + [-np.inf] * 3 + [-1.] * 3 # +-1000 is an overestimate from visual inspection, hopefully it will be fine
+ [0.] + [0.] + [0.] + [-1.] + [0.] * 4 + [0.] * 4 + [0.] * 4,
dtype=np.float32
),
np.array(
(([1e3] * 6) + ([1.] * 3)) * 40 + [np.inf] * 3 + [np.inf] * 3 + [1.] * 3
+ [np.inf] + [1.] + [1.] + [1.] + [1.] * 4 + [np.inf] * 4 + [np.inf] * 4,
dtype=np.float32
),
dtype=np.float32
),
action_space=Box(low=-1., high=1., shape=(2,)),
)
# DL framework to use.
.framework(args.framework)
# Create a "chatty" client/server or not.
.callbacks(CustomCallbacks)
# Use the `PolicyServerInput` to generate experiences.
.offline_data(input_=_input)
# Use n worker processes to listen on different ports.
.rollouts(
num_rollout_workers=args.num_workers,
recreate_failed_workers=True,
)
# Allocate resources
.resources(
num_gpus=args.num_gpus,
num_cpus_per_worker=worker_cpus,
num_gpus_per_worker=args.num_gpus_per_worker,
)
# Disable OPE, since the rollouts are coming from online clients.
.evaluation(off_policy_estimation_methods={})
# Set to INFO so we'll see the server's actual address:port.
# .debugging(log_level="WARN")
)
if args.layer_size > 0 and args.layer_count > 0:
config.model.update(
{
"fcnet_hiddens": [args.layer_size] * args.layer_count,
}
)
if args.run == "SAC":
if args.layer_size > 0 and args.layer_count > 0:
config.q_model_config.update({
"fcnet_hiddens": [args.layer_size] * args.layer_count,
})
config.policy_model_config.update({
"fcnet_hiddens": [args.layer_size] * args.layer_count,
})
checkpoint_path = CHECKPOINT_FILE.format(args.run)
# Attempt to restore from checkpoint, if possible.
if not args.no_restore and os.path.exists(checkpoint_path):
checkpoint_path = open(checkpoint_path).read()
else:
checkpoint_path = None
stop = {
"training_iteration": args.stop_iters,
"timesteps_total": args.stop_timesteps,
"episode_reward_mean": args.stop_reward,
}
tune.Tuner(
args.run, param_space=config, run_config=air.RunConfig(stop=stop, verbose=args.verbose),
).fit()