I’m trying to implement an architecture similar to that of SEED RL, and I would love to have a few tips regarding the implementation.
More specifically, I want to implement a centralized GPU inference worker. It will accept inference queries from multiple actors, run the inference on GPU with a single large batch, then return the results to the actors. What are the best options to implement such a thing? Right now I’m thinking about using ray.util.queue or ray.serve.batch.
Hey @uduse , could you look at the example here and give me some feedback as to whether this makes sense as a possible solution here? I added it to the lib a few weeks ago thinking this may be useful for some use-cases
Hi @sven1977 , I look through the example and it seems it’s irrelevant to what I’m asking. A more appropriate question for me ask is maybe:
Say I have three agents, A, B, C, and all of them want results from policy.compute_single_action. However, doing policy.compute_actions by batching requests from A, B, C is much faster than doing three policy.compute_single_actions. What’s the best way to achieve this?
My current idea is, let A, B, C sit in the same process, and make requests by queuing data into a shared ray.util.queue.Queue. Then, in a separate process that handles inferences, call queue.get_nowait_batch and process the data in a big batch, and send back to A, B, C respectively.
(I’m not actually using policy.compute_single_action, just as an example)
Or, say I want to perform a search similar to the example here. Here, compute_priors_and_value is slow because it makes the forward pass with a batch size of 1.
With SEED architecture here:
Multiple such searches (say 1000 of them) would await for their inference requests and a remote process would handle all the inferences requests at the same time and send back the right data to the right requester as responses (or a single response somehow).
I think you can already accomplish what you want with rllibs current implementation.
The config setting you want to look at is “num_envs_per_worker” if you set that to > 1 then each of those environments observation s will be batched together.
If you set “num_workers” to 0 and “create_env_on_driver” to true then the rollouts and training will all happen on the learner.
You could of course set num_workers to > 0 and have parallel rollout with batched envs in each rollout worker.
Thank you for your response I think this batching would work on the environment side. However, what if something that’s within the policy graph needs to be batched a big forward pass?
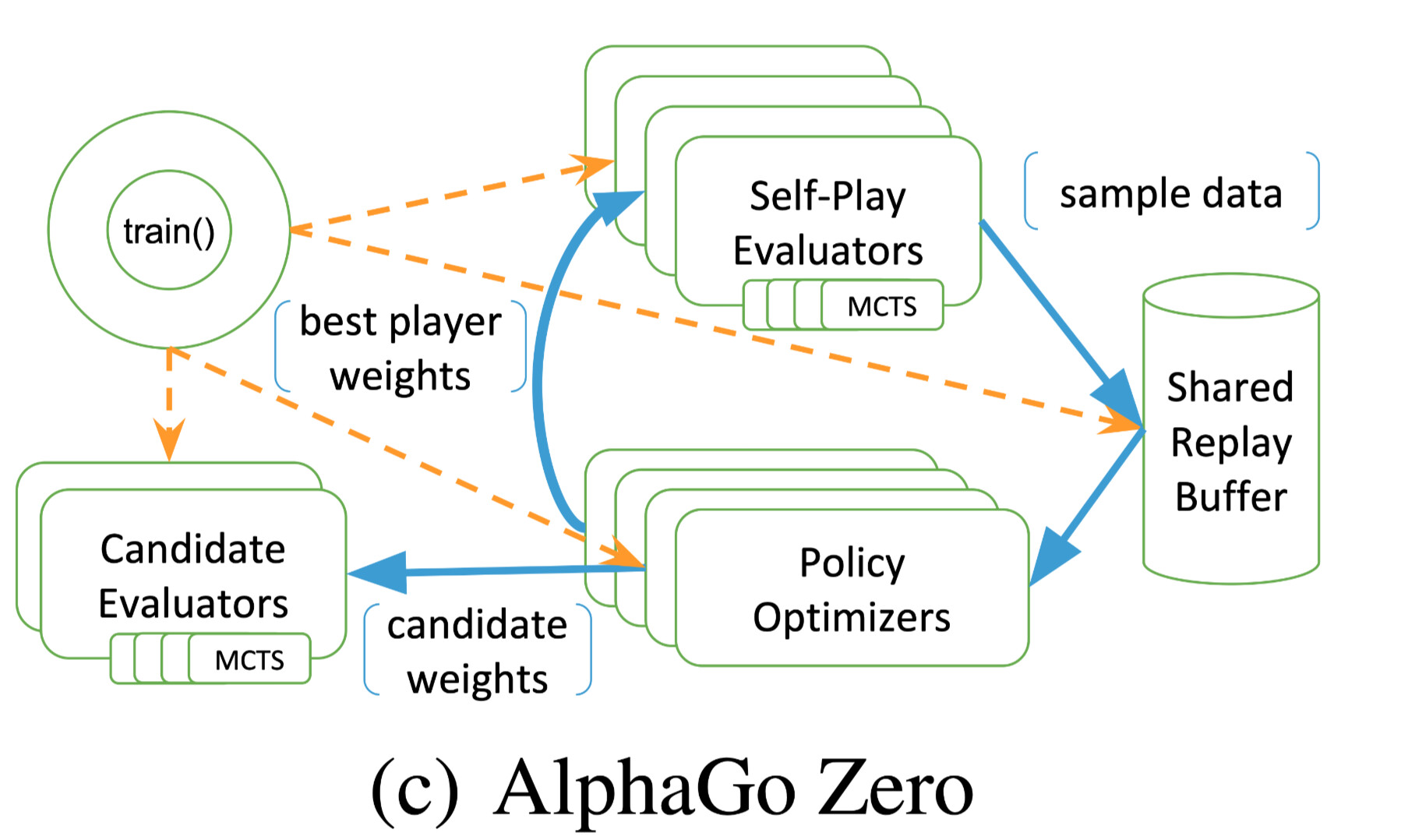
More concretely, say we have this AlghaGo Zero structure above, and we run searches in the self-play evaluators. The searches need to infer value of states on leaf nodes, so multiple inferences with a batch size of 1 are required. (See this specific implementation in RLlib here) However, I would like to also batch these inferences because it’s currently the bottleneck of my system. It seems there’s no native support to batch this kind of inference, am I right?