Hey, all. A while ago, I started on a project that entailed use of a shared critic. I saw pettingzoo_shared_value_function.py, and was eager to use it as a reference, but I found that it wasn’t yet implemented, and the file was a temporary placeholder. Having now completed the implementation of my shared critic using the new API stack, I thought that I should adapt my code for the example and share my implementation with other developers who might need to do something similar.
My PR is here, and I wanted to ask whether I had submitted it in the correct way. I’ve made one successful pull request before, but that one involved fixing an already-implemented feature rather than implementing an empty file earmarked for new code, and I wanted to make sure that I’m following the right procedure. I’d also like to make sure that my shared critic implementation is in line with RLlib’s best practices, both for the benefit of the pull request and for the sake of my own project, which presently uses a similar implementation.
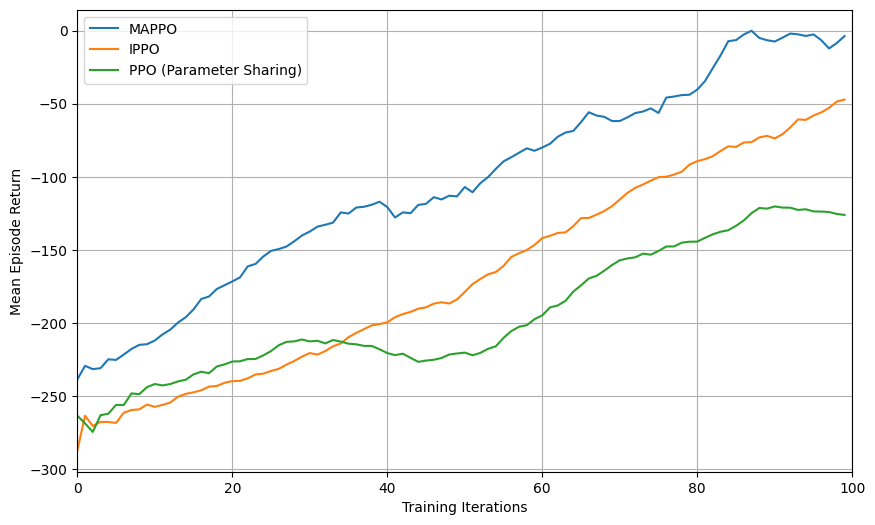
I’ve tested the code out, and performance is in line with what I’d expect, with the shared critic outperforming both independent learning (pettingzoo_independent_learning.py) and full parameter sharing (pettingzoo_parameter_sharing.py), on account of its being able to take advantage of the benefits of both approaches (the flexibility mentioned in the comments of the former, and the latter’s ability to more completely leverage both agents’ training data). A graph of reward over three fairly representative training runs is below:
Please let me know if there’s anything I can do to improve my code, or if there is a different procedure I should follow for helping to implement this example script.