

I am modifying my code by referring to this example.
Since my source code is made to have multiple agents follow one policy,
config[‘multiagent’] ['policy_mapping_fn '] was like
" policy_mapping_fn = lambda x : original policy "
By the way, I wanted to make one of these agents follow a policy other than the original policy.
so,
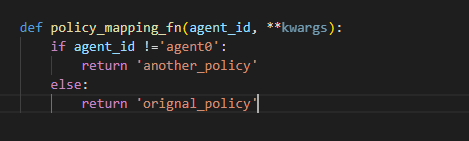
The code was written as shown in the example above.
And then, it’s execution result seemed that ‘one policy’ was assigned to ‘every agent’ except ‘agent0’. (one policy per one agent)
Can you tell me how to modify the code to have ‘multiple agents(exept ‘agent0’)’ refer to ‘only one policy’ ?
thank you. Have a nice day.