How severe does this issue affect your experience of using Ray?
High: It blocks me to complete my task.
Hi,
Is there a way to train multiple trainers(like PPOTrainer …) in same environment?
more exactly, I want to embed trained trainer(lr = 0) in environment while other new trainer being trained. so, new trainer trained in environment that containing trained trainer.
I tried this way: I manipulated the environment to have some agents perform actions calculated from the trained policy, but they were not perfect.
So, I would manipulate training stage.
Can you please help me?
I’m using ray.tune.
Thank you.
Can you provide a little more information on your setting, please?
Here is what I understand: You use a multi-agent env, you want one agent in the env to be frozen to a perfect policy and another one to train as usual?
If so, you should implement the perfect policy by hand and use Rllib’s multi-agent capabilities.
Have a look at this example if you want to learn more.
I am modifying my code by referring to this example.
Since my source code is made to have multiple agents follow one policy,
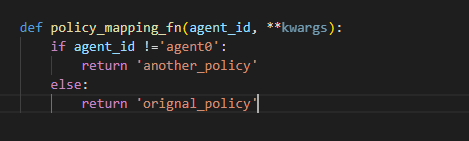
config[‘multiagent’] ['policy_mapping_fn '] was like
" policy_mapping_fn = lambda x : original policy "
By the way, I wanted to make one of these agents follow a policy other than the original policy.
so,
The code was written as shown in the example above.
And then, it’s execution result seemed that ‘one policy’ was assigned to ‘every agent’ except ‘agent0’. (one policy per one agent)
Can you tell me how to modify the code to have ‘multiple agents(exept ‘agent0’)’ refer to ‘only one policy’ ?
thank you. Have a nice day.