When I submit some jobs to a header node, the job API became unstable. Head node has a lot of resources, like CPU and mem. But the concurrency capability is still not very good. Here are the some cases:
- When there are over 30 running jobs, for example, Submitting jobs with jobs api became easy to fail. What I mean is not just that there will be a lot of pending jobs, Instead, submit an interface error or timeout. I am curious why the concurrency ability is several orders of magnitude weaker than I imagined.
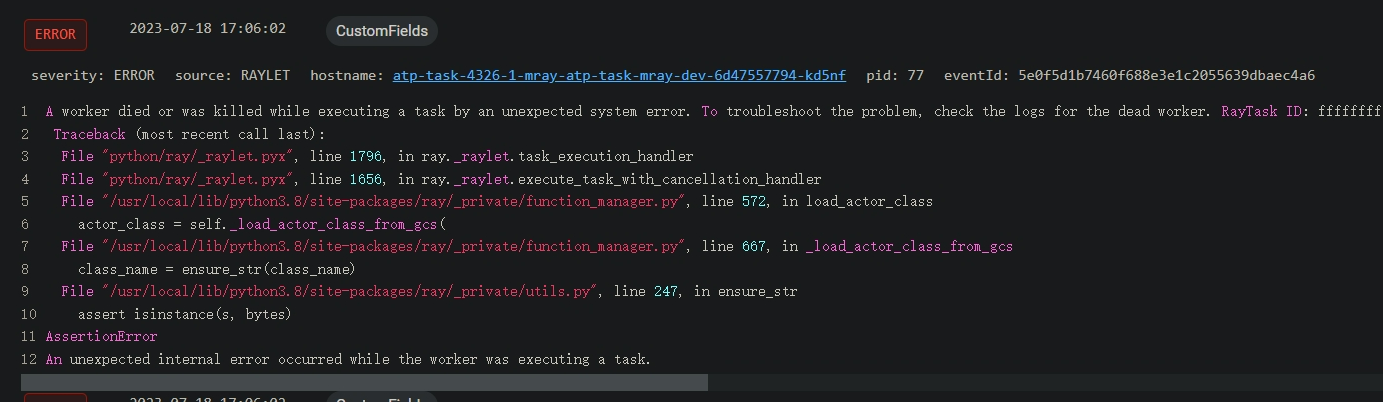
- Still the scene above, some pending jobs or running jobs easy to become a failed state.I can confirm that this is not the job itself failed. I consider that it may caused by job agent itself.
Unexpected error occurred: The actor died unexpectedly before finishing this task.
- some loading errors like these:

- When over 400 jobs are completed, new job cannot submit successfully any more.
- Besides submitting interfaces, Under high load conditions(Only a few dozen tasks), stop job API and some other job related api also unstable.
Any advice? Close log redirection to head node will help?
Versions / Dependencies
2.5.0
One tip:
- avoid scheduling tasks/actors on your head node by setting cpu=0, gpu=0 when starting your head node. The job api/agent may fail if your head node is under heavy load. This ensures that your head node can focus on the orchestration and management of the nodes and jobs even under many concurrent jobs.
With this tip in mind, I did some manual scalability tests before:
At the same time, we do plan to work with the OSS community to support better retention mechanism for ray jobs [Dashboard] Add job retention mechanism · Issue #35700 · ray-project/ray · GitHub. Hope that it will resolve some of your concerns.
Thanks for your reply sun~ Thanks for your advice. Actually, i do a lot of works to improve head node stability, include you mentioned that avoid jobs running on the head node by set cpu=0.
The head node I configured has over 20 cores of CPU, it is difficult for jobs that are running at the same time to break through 50. May it be related to the concurrency of my task itself?
Besides, I used working_dir, but the content in the folder is not large and may be less than 2MB. Does this also increase the burden on gcs?
My worker will produce a certain amount of logs, but the overall scale is not too exaggerated. I would like to further reduce the burden of GCS by redirecting logs to the head node
What’s the cpu and memory usage of the head node when the jobs start to fail?
If this is due to overloaded head node, you should be able to tell from its hardware usage